It has been around one year since I wrote the post about how the fourth industrial revolution (aka digital revolution) is affecting our lives. The digital transformation of the diverse sectors on which the society depends is changing the rules of the game. The development of storage technologies and big data analytics open new horizons to improve the services we consume every day and our quality of life. The post ended with the fact that the railway transport is one of the most digitised sectors over the last years. The progressive digitalisation of railway systems is producing a huge and diverse amount of data that can transform the management systems, including the safety management systems.
From the safety science perspective, the unstructured text is one of the most valuable type of data as it is the common way of gathering information from accidents, incidents and near misses. Accident reports describe events that unfortunately have serious consequences such as injuries and high economic costs. Incidents describe events without serious consequences such as trespasses of railway premises. Finally, near misses describe potentially dangerous events such as a hole on the platform. Even though there is abundant research that analyses the relation between accidents, incidents and near misses, the extraction of information from their unstructured text to improve the safety management is one of the main challenges of the digitalisation of railway.
Although the number of accidents and incidents are not too high, the number of near misses may amount to several hundred thousand per year (e.g. 150.000 per year in UK). This huge volume of text records requires considerable human effort to its interpretation and its manual processing has important drawbacks. The first one is that the interpretation of the text depends on the experience of the reader and significant information could be lost. The second one is that the knowledge is acquired by the reader. If that person leaves the organisation, the knowledge is lost. Finally, the extracted information is not combined with other data sources. The Natural Language Processing (NLP) is the research field that combines linguistics and computer science to solve these problems. NLP automates the processing of text sources and gives structure to the information for its combination with other data sources. For example, the information extracted from near misses that describe visibility problems with a railway signal could be combined with other data sources that provide information about violations of train drivers such as passing a red signal. This combination of information would provide more insight and knowledge about whether the cause of the violation is related to the visibility of the signal.
The main challenges of applying NLP techniques in railway safety are the ambiguity of the natural language and the extraction of terms (multiple words that represent one concept), in particular, the terms that are associated to technical domains such as the railway safety domain. One of the approaches that faces these problems is the conversion of text into a graph. A graph is just a collection of nodes that are connected to each other by means of relationships. For example, image your Facebook network. Users of Facebook would be the nodes of the graphs and the relationship between the nodes would be a relationship of friendship between users. In the case of a piece of text, the nodes would represent words or terms and the relationships would represent the closeness between words or terms.
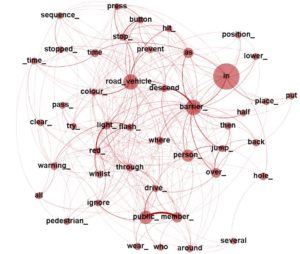
Representing text as a graph provides two great advantages. The first one is that the topology of the graph such as the size of the nodes and the width of the relationships can be analysed to assess the relevance of words and find new terms. For example, the figure shows that the term road_vehicle and the word barrier are relevant nodes because of their size and they are also very connected. Likewise, other nodes such as public and member have a very strong relationship that means a new a term. The second advantage is related to how people store information in their brain and how this process can be simulated in a computer. From the cognitive point of view, our brains store the perceived information into abstract structures called schemas. These schemas form a sematic network that influences in the way people reason. For example, if a person without railway safety knowledge perceives the word “derailment”, automatically his or her semantic network would link its meaning with generic concepts such as “accident”. However, a railway safety expert would link the word with concepts such as “overspeed”, “failure in the braking system” and “wheel defects”. The way in which a semantic network can be understood by a computer is a graph of concepts called ontology. Ontologies are built by experts and can represent the knowledge of technical domains. The combination of ontologies with graphs of text enables the application of machine learning that updates the ontology as it was the learning process of a person.
These two advantages are the core of the artificial intelligence that allows to automate the classification of the accident, incident and near misses reports and the extraction the main hazards and threats from the text. This information can also be structured to be combined with other data sources in order to apply big data techniques that provides a better understanding of the railway safety as a whole.
By Dr Miguel Figueres-Esteban, Research Fellow, Institute of Railway Research, University of Huddersfield. SRUK Yorkshire Constituency.
More information in:
https://www.elpais.com.uy/vida-actual/alibaba-crea-modelo-aprendizaje-artificial-gana-mente-humana.html
http://www.agenciasinc.es/Noticias/Un-sistema-multilinguee-para-combatir-la-ambigueedad
http://www.clinical-innovation.com/topics/ehr-emr/natural-language-processing-system-identifies-care-quality-through-ehrs
http://www.eltiempo.com/tecnosfera/novedades-tecnologia/la-inteligencia-artificial-de-watson-que-aprende-el-lenguaje-y-supera-a-los-humanos-170728