Ya ha pasado prácticamente un año desde que os contaba en otra entrada del blog de CERU que la humanidad estaba entrando en un nuevo punto de inflexión: la cuarta revolución industrial o revolución digital. La transformación digital de diferentes sectores de los que depende la sociedad está cambiando las reglas del juego con las que vivimos. El avance de las tecnologías de almacenamiento de datos, junto con estrategias basadas en analíticas big data, abren nuevos horizontes para mejorar no sólo los servicios que diariamente consumimos, sino también nuestra calidad de vida. Concluí mi anterior entrada en este blog señalando que el transporte ferroviario es uno de los sectores que más se ha digitalizado durante los últimos años. La digitalización progresiva de los sistemas ferroviarios está produciendo una cantidad inmensa y variada de datos que podrían revolucionar los sistemas de gestión ferroviarios, entre los que se incluye los sistemas de gestión de la seguridad.
Desde la perspectiva de la ciencia de la seguridad, el texto en formato no estructurado es uno de los tipos de datos más valiosos que se puede encontrar ya que es el modo natural en el que se recoge la información de los accidentes, incidentes y cuasi-incidentes. Los informes de accidentes describen los eventos que, desgraciadamente, han producido consecuencias fatales como la pérdida de la vida de personas o grandes pérdidas económicas en daños materiales. Los incidentes describen situaciones que finalmente no tuvieron consecuencias graves, como pueden ser infracciones de personas como cruzar una vía por lugares no autorizados para ello. Finalmente, los cuasi-incidentes son avisos enviados por el personal ferroviario que describen posibles situaciones peligrosas que aún no han ocurrido pero que podrían evitar futuros incidentes o accidentes. Por ejemplo, imaginad un socavón en un andén de la estación, el personal de la estación informaría que se ha detectado un socavón y que alguien podría tropezar y hacerse daño. Si bien existe abundante investigación que analiza la relación entre accidentes, incidentes y cuasi-incidentes, la extracción de información de sus textos para mejorar a la seguridad ferroviaria es uno de los mayores retos que afronta la digitalización del ferrocarril.
Aunque el número de accidentes o incidentes afortunadamente no es muy elevado, el número de cuasi-incidentes puede ascender a cientos de miles por año (por ejemplo 150.000 por año en Reino Unido), requiriendo un esfuerzo humano considerable para la interpretación y extracción de información. Asimismo, la extracción manual de la información posee importantes desventajas. La primera desventaja es que la interpretación del texto depende de la experiencia y conocimientos de quien lo lee, pudiendo perderse información que podría ser relevante. La segunda es que el conocimiento extraído reside en la persona, si esa persona deja la organización, todo el conocimiento adquirido se pierde. Finalmente, la información extraída por una o varias personas no se suele combinar con otras fuentes de información. El procesamiento del lenguaje natural (NLP en inglés) es el campo de investigación de la lingüística y la informática que intenta buscar soluciones a estos problemas, permitiendo automatizar parte del procesamiento de fuentes de datos de texto y estructurando la información para su combinación con diferentes fuentes de información de diversa naturaleza. Por ejemplo, información extraída del texto de cuasi-incidentes que describen problemas de visibilidad de una determinada señal ferroviaria debido a abundante vegetación a su alrededor, podría combinarse con otras fuentes de información que detectan infracciones de maquinistas, como pasar una señal en rojo, para determinar si ha habido problemas de visibilidad en el reconocimiento de dicha señal.
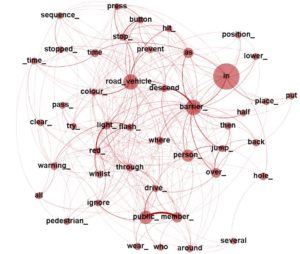
Los principales retos de investigación del procesamiento del lenguaje en el ámbito de la seguridad ferroviaria residen en la ambigüedad inherente del lenguaje y en la detección de términos compuestos (varias palabras juntas que representan un solo concepto), en particular, aquellos que son propios de un dominio técnico específico como la seguridad ferroviaria. Una de las aproximaciones que mejor los afronta es la conversión del texto en un grafo. Un grafo es una estructura que se compone de nodos y relaciones entre nodos. Por ejemplo, imaginad vuestra red de Facebook. Los usuarios de Facebook se representarían como nodos y las relaciones entre nodos representarían una conexión por amistad. En el caso de un fragmento de texto sería lo mismo, cada nodo representaría una palabra o término compuesto y las relaciones indicarían cómo de próximas están esas palabras o términos.
El hecho de tener el texto en un formato de grafo ofrece dos grandes ventajas. La primera es que se puede analizar la estructura del grafo como el tamaño de los nodos o el grosor de sus relaciones para determinar la importancia de las palabras o detectar nuevos términos compuestos. Por ejemplo, en la figura se observa que palabras como road_vehicle y barrier son importantes por su tamaño (tienen muchas conexiones con otras palabras) y al mismo tiempo están muy relacionadas (son muy amigas). Pero también podemos detectar un nuevo término con la combinación de las palabras public y member. La segunda ventaja está relacionada con el modo en que las personas almacenamos la información en nuestro cerebro y cómo se puede replicar dicho proceso en un ordenador. Desde el punto de vista cognitivo, nuestro cerebro almacena la información que percibimos en estructuras abstractas denominadas schemas, que forman una red semántica que determina la manera en la que razonamos. Por ejemplo, si una persona sin conocimientos ferroviarios percibe la palabra “descarrilamiento”, automáticamente su red semántica podría ligar su significado al concepto de “accidente”. Sin embargo, la red semántica de un experto en seguridad ferroviaria podría ligar su significado a conceptos como “exceso de velocidad”, “fallo de sistema de frenado” o “rotura de la rueda”. El modo en que podemos representar una red semántica en algo que pueda entender un ordenador es un grafo de conceptos que se denomina ontología. Las ontologías son elaboradas por expertos y pueden representar el conocimiento de un dominio técnico específico. La combinación de ontologías con grafos que provienen de textos permite la aplicación de técnicas de aprendizaje automático que actualizan los conceptos de las ontologías como si fuera el proceso de aprendizaje de una persona.
Estas dos ventajas son el corazón de la inteligencia artificial que permite la clasificación de informes de accidentes, incidentes y cuasi-incidentes y la extracción de los principales peligros y amenazas que contiene el texto sin tener que leerlos manualmente. Esta información, ya estructurada, se puede combinar con otros tipos de datos para la aplicación de técnicas basadas en big data que permitan entender mejor el estado de la seguridad del ferrocarril en su conjunto.
Por Dr Miguel Figueres-Esteban, Investigador postdoctoral, Institute of Railway Research, University of Huddersfield. SRUK Delegación de Yorkshire.
More information in: